Hardcover's Book API: A great Goodreads alternative
I’m a longtime Goodreads user, but have always wanted to try something better when it comes to tracking my books. So I’ve recently started using Hardcover, a competitor run by a small indie team. It’s still in the early days, and I know it’s hard to beat something as large as Goodreads, but I’m hopeful!
Goodreads used to have an API, which unfortunately got discontinued a couple of years ago. One of the great things about Hardcover is that it is really developer-friendly They have a GraphQL API that is free-to-use and lets you query on your book reviews and for any data on the books that are stored in Hardcover. It also can be used to do basically anything you would be able to do yourself in the Hardcover UI, like update the status of books you are reading, add books to lists and more.
How I’m using Hardcover’s API
Right now I’m using the API to generate the book reviews section of my site. I fetched all my reviews from Hardcover, and am storing them in a JSON file. I then loop through the reviews in this list, and render them all on the page.
I had a bit of fun with it, and so my current design has a notebook theme. I have all my reviews listed as though they are on one long notepad. You can also filter by genre and star rating.

And my favourite part - the review is rendered inside of a cute little notebook. I took inspiration from the stationery brand Field Notes for this one.

Getting started with Hardcover’s API
Hardcover’s API is also still in an early-access mode, but they’ve recently started to make a start on their documentation here. In this post I’ll go over some of the queries I found useful so far. Hardcover’s Discord server is also a great place to get answers to your questions.
You’ll first need to go to your settings page, and get your Hardcover API key. Then you can test out your queries in Hardcover’s GraphQL console.
Getting all the books you have read
Starting off with a basic GraphQL query, we can filter using the status_id to get a list of titles of all the books you have marked as “read” in Hardcover:
{
me {
user_books(where: {status_id: {_eq: 3}}) {
rating
book {
title
}
}
}
}We’ve wrapped it in me which is what you can use to query on anything specific to your user.
The way the status_id value works is:
- 1: A “want to read” book
- 2: An “currently reading” book
- 3: A “read” book
- 5: “A did not finish” book
Getting the author of a book
If you search for cached_contributors, you’ll get an array containing a list of “contributors” to a book. This will contain a predetermined set of data, like the contributor’s name, ID, and image.
book {
cached_contributors
}The reason they’re “contributors” and not “authors” is that it can also contain the names of people who have translated the book. If there are multiple authors, they will also all be in the list. If you’re querying on a regular fiction book with one author, using the first item in the list will usually be fine.
The cached version is faster to query, but if there was something specific you wanted, you can also query on the non-cached contributions:
book {
title
contributions {
author {
name
}
}
}Getting a book’s Hardcover URL
If you wanted to get the book’s link on Hardcover, you can query for its slug:
book {
slug
}A slug is the string after the domain name of the website, e.g. on emgoto.com/hardcover-book-api, the “hardcover-book-api” bit is the slug.
So once you get the slug, you’ll just need to prepend https://hardcover.app/books/ to the beginning of it to create your Hardcover URL.
Getting the genre tags on a book
The genre tag system in Hardcover is user-generated. You can query on the cached_tags, which will return you the tags in order from most-tagged to least.
book {
cached_tags
}Once you have the full list of tags, you can use cached_tags['Genre'] to get the genre-specific ones.
If a lot of people have tagged a particular book as fiction, that will be the first genre that shows up in the list. Interestingly people love to tag their books as fantasy, and so this genre often shows up before the fiction tag. People love tagging their books as fantasy so much, that sci-fi books like Dune even end up with both sci-fi and fantasy tags as well.
If you are going to use this data, I recommend doing a little bit of clean-up on it first. For example if the book has both fantasy and sci-fi as a genre tag, only use the one that comes first in the list and discard the other one, since that is more likely to be accurate.
Adding a book to your “to read” list
So far I’ve only touched on fetching data, but you can also use Hardcover’s API to manipulate data - of course you can’t touch anyone else’s things, but anything that you could do on your own Hardcover account is fair game.
If you have a book’s ID, you can add it to your “to read” list by setting its status_id to 1:
mutation addBook {
insert_user_book(object: {book_id: 123, status_id: 1}) {
id
}
}Getting your book reviews
This is what I use to fetch all the reviews I have written in Hardcover:
{
me {
user_books(
where: { _and: [
{has_review: {_eq: true}},
{status_id: {_eq: 3 }}
]}
order_by: [
{ date_added: desc },
{ reviewed_at: desc }
]
) {
reviewed_at
date_added
review_raw
rating
book {
title
}
}
}
}Nearly all of my books and reviews are imported from Goodreads, and I think sometimes the data gets a little bit messed up in the import. I found that sorting it by both dated_added and reviewed_at was more accurate.
I used the review_raw value to get the review text, which is doesn’t include any formatting like newlines. This unfortunately means if you have multiple paragraphs in your review, the API spits it out all as one long paragraph like this:
this is the end of one paragraph.And this is the start of the nextWith JavaScript, I got around this by doing a regex like the following:
const text = review_raw
.replace(/(?<=[.!?])(?=[A-Z])/g, '\n\n');If there are any periods with no spaces after them, you can make a guess that this should be a new paragraph and add the double newline \n\n. Which creates a new paragraph.
Another downside is that spoiler tags are also missing, so you’ll have to add these in manually.
There is also a review_html value, which I thought might be more useful, but unfortunately it always seems to be null for me. Similarly, if you have a review with spoilers, there is a review_has_spoilers value, but for all the books I’ve imported from Goodreads, this value is false so you may not be able to rely on it.
Searching for a book by title
Hardcover recently released a new search API. For example, if you wanted to search for a book by it’s title, you would input the following:
{
search(
query: "dune",
query_type: "Title",
per_page: 5,
page: 1
) {
results
}
}You can’t get any more specific than results - this just returns a huge blob of data, so you would then have to parse through it yourself to get the info you need. It seems to at least return Dune as the first result in the array, but oddly enough Jane Eyre in second in the list, so I’m not really too sure how well this search works behind-the-scenes.
Previously you were able to do stuff like this using the _eq operator:
{ books ( order_by: {users_read_count: desc} where: {title: {_eq: "Dune"}} limit: 5 ) { title }}But unfortunately they had to remove that from the API due to performance concerns.
Getting books in your Hardcover Lists
As well as the standard “want to read” and “read” lists, Hardcover also has a separate custom lists feature. To grab all of your lists, and the books inside of them, you can do the following:
{
me {
lists(order_by: {created_at: desc}) {
id
name
slug
list_books {
book {
title
}
}
}
}
}Adding a book to a list
If you wanted to add a book to a list, first you would need to grab the list ID and the book’s ID. Then it’s easy as the following:
mutation addBook {
insert_list_book(object: {book_id: 123, list_id: 123}) {
id
}
}Making an API call with JavaScript
Once you want to move out of the GraphQL console, you can make API calls using fetch(). As a really quick example, here’s me fetching all my reviews (I’ve abbrievated it down a bit):
const HARDCOVER_API_KEY = 'Bearer ...';
const query = `
{
me {
user_books(
where: {has_review: {_eq: true}}
order_by: [
{ date_added: desc },
{ reviewed_at: desc }
]
) {
review_raw
rating
book {
title
}
}
}
}`;
const fetch('https://api.hardcover.app/v1/graphql', {
headers: {
'content-type': 'application/json',
authorization: HARDCOVER_API_KEY,
},
body: JSON.stringify({ query }),
method: 'POST',
})
.then((response) => response.json())
.then(({ data }) => {
const reviews = data.me[0]['user_books'].map(review => {
// Just as an example of what you could do
const author = cached_contributors[0].author.name;
console.log("author!", author);
});
});A programming pro-tip that I have to make constructing fetch calls easier is if you:
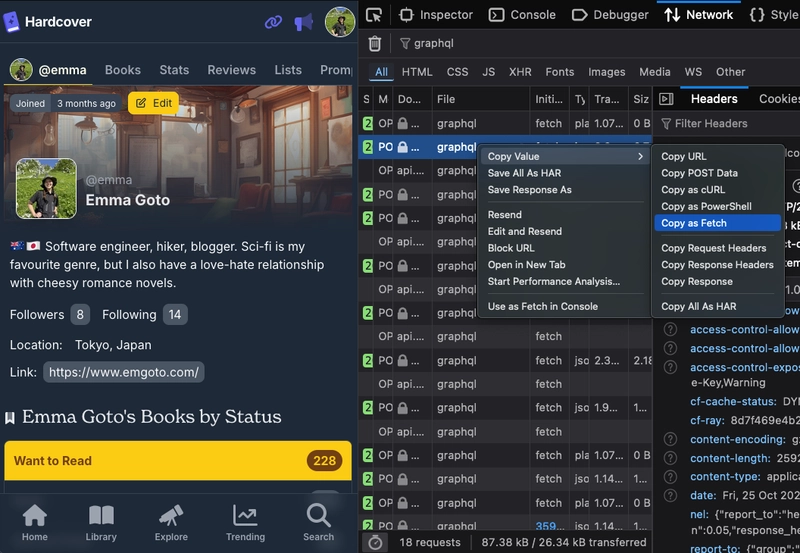
- Go to Hardcover
- Search for
graphqlin the Network tab - Find one that looks useful and is returning info
- Right click the network call > Copy > Copy as fetch
It will copy for you a fetch call similar to the one I’ve pasted above, which you can then use in your own code.
A note on rate limiting
Once you move out of the GraphQL console and start doing things in a script, you may run into errors or rate limiting issues if you try and do too many things at the same time.
For example, when adding a new book to a list, I find that trying to add two at the same time will error in the API, probably because it is trying to add two books to the same position in the list.
Similarly, if you tried to make 100 different calls to search for a book based on its title, some of these calls will time out. If you spread them out and do one every second like the following, then you shouldn’t have any issues:
let delay = -1000;
const delayIncrement = 1000;
const addBooksToList = async () => {
const promises = books.map((book) => {
delay += delayIncrement;
return new Promise((resolve) =>
setTimeout(resolve, delay))
.then(() => addBookToList(book.id))
});
const results = await Promise.all(promises);
};Also, if you grabbed the image URL of a book from Hardcover, and then attempted to load the images of 100 books at the same time on your page, the API will rate limit you, and some of the images will not load. I recommend putting a loading=lazy in your image tags like so:
<img
loading="lazy"
src={image.url}
/>This way, the images will only load when a user scrolls down to view them.
And that’s it! I’m keen to see where Hardcover goes next - I’m hoping it does well, and finally we have a Goodreads-killer on our hands. If you’d like to follow me on Hardcover, I fortuitously have managed to snag the @emma handle.